 Englisch
Englisch  Chinesisch
Chinesisch  Deutsch
Deutsch  Koreanisch
Koreanisch  Japanisch
Japanisch  Farsi
Farsi  Portuguese
Portuguese  Russian
Russian  Spanisch
Spanisch 
5--Instance segmentation

In addition to semantic segmentation, instance segmentation segments instances of different classes, such as marking five cars in five different colors. In the classification, there is usually an image in which one target is the focus and the task is to say what the image is. But in order to split the instance, we need to perform more complex tasks. We see complex spots with multiple overlapping objects and different backgrounds. We not only classify these different objects, but also determine the boundaries, differences and relationships between them!

So far, we have seen how to use CNN features in many interesting ways to effectively locate different targets in images with bounding boxes. Can we extend these techniques to locate the exact pixels of each target, not just the bounding box? Explore the instance segmentation problem on Facebook AI using an architecture called Mask R-CNN.
Like Fast R-CNN and Faster R-CNN, the underlying principle of Mask R-CNN is simple. Given that Faster R-CNN works very well in target detection, can we extend it for pixel-level segmentation?
Mask R-CNN does this by adding a branch to the Faster R-CNN, which outputs a binary mask that indicates whether a given pixel is part of the target. This branch is a full convolutional network based on the CNN's feature map. Given the CNN feature map as input, the network outputs the matrix at all positions with 1s in the pixel belonging to the target, and outputs 0 (this is called binary mask) elsewhere.
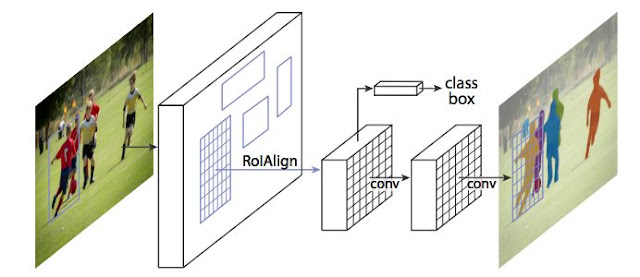
In addition, when running on the original Faster R-CNN architecture without modification, the area of the feature map selected by RoIPool (pool of interest area) is slightly out of alignment with the area of the original image. Since image segmentation requires pixel-level specificity, unlike a bounding box, this naturally leads to inaccuracies. Mask R-CNN solves this problem by adjusting RoIPool to more precisely align by using a method called RoIAlign (region of interest alignment). In essence, RoIAlign uses bilinear interpolation to avoid rounding errors, resulting in inaccurate detection and segmentation.
Once these masks are generated, Mask R-CNN combines them with the classification and bounding boxes from Faster R-CNN to generate such an accurate segmentation:

in conclusion
These five major computer vision technologies help computers extract, analyze, and understand useful information from one or a series of images. I haven't talked about many other advanced technologies, including style shifting, coloring, motion recognition, 3D objects, body pose estimation, and more. In fact, the cost of computer vision is too high to be explored in depth, and I encourage you to explore it further, whether through online courses, blog tutorials or official documentation. For beginners, I highly recommend the CS231n course because you will learn how to implement, train and debug your own neural network. As a bonus, you can get all the presentation slides and homework guides from my GitHub repository. I hope it will guide you to change your view of the world!
Follow Me





